지금까지 벡터, 행렬, logical, 문자형 데이터들에 대해 다루었다. 그런데, 실제로 다루게 되는 데이터들은 단순히 숫자로만 구성되었거나, 참/거짓으로만 표현할 수 있거나, 글자로만 구성된 데이터들만은 아닐 것이다. 실제 처리하게 되는 데이터들은 정말 그 때 그 때 “다른 형태와 구조” 를 가지고 있다. 예를 들면 아래와 같은 경우가 있을 수 있다.
- 데이터가 들어온 순서가 매우 중요하지만 각 순번의 데이터 끼리는 크기도 다르고 형식도 다른 경우. 가령, 문자와 숫자를 순번에 맞춰 한번에 다루는 경우가 될 수 있다.
- 데이터의 구조가 중요한 역할을 하는 경우. 가령 어떤 고등학교 학생들을 학년, 반, 번호 순서로 매겨서 관리하면 다수의 학생들을 관리하기가 편하다. 동명이인의 학생이라고 하더라도 몇 학년, 몇 반, 몇 번 학생인지에 따라 누가 누구인지 정확하게 구별해낼 수 있다.
- 모든 데이터들이 동일한 특성을 공유하고 있어서 테이블 형태로 표현하기 적합한 경우. 가령, 성적표 데이터를 다룰 때 모든 학생들이 동일한 과목의 시험을 치른 경우가 될 수 있다.
1번의 경우에는 cell형 배열을 쓰는 것이 좋고, 2번의 경우에는 구조체(struct) 배열을 쓰는 것이 좋다고 할 수 있다. 3번의 경우는 table형 배열을 사용하는 것이 좋다.
cell형 배열
cell형 배열은 “셀(cell)”이라는 데이터 컨테이너를 사용하는 데이터 타입이다. 셀의 가장 큰 특징은 어떠한 데이터 형이라도 들어갈 수 있다는 점이다.

cell형 배열의 생성
셀 형 배열은 중괄호 {} 를 이용해 생성한다. 벡터나 행렬이 대괄호 [] 를 이용해 생성하는 것과 구분해야한다.
예를 들어 아래와 같이 임의의 cell형 배열을 정의할 수 있다. 정의된 변수을 보면 네 개의 cell 원소들에 들어있는 데이터 타입은 다 다른 것을 알 수 있다.
my_cell = {143, 'abc', true, "foo"}
my_cell =
1×4 cell array
{[143]} {'abc'} {[1]} {["foo"]}
그리고 cell형 배열을 생성하면 아래와 같은 아이콘이 나온다는 것을 알 수 있다.
cell형 배열의 인덱싱
셀 배열을 사용할 때 헷갈리는 부분 중 하나는 셀 배열에 들어있는 데이터에 접근하는 방법이다. 셀 배열의 데이터에 접근할 수 있는 방법은 총 두 가지이다. 중괄호 {}를 이용하거나 소괄호 ()를 이용하는 것이다. cell의 내용에 접근하기 위해선 중괄호 {}를 이용해 인덱싱해준다. cell “덩어리”들에 접근하기 위해서는 위해서는 소괄호 ()로 인덱싱해준다.

cell형 배열에 인덱싱 하는 방법이 두 가지로 구분되는 것은 cell을 다룰 때 어떤 목적으로 다루는지에 따라 방법이 구분되어야 하기 때문이다. 중괄호를 이용하여 셀을 인덱싱할 때는 셀 내부의 내용물에 관심이 있는 경우이다. 보통 셀을 이용하는 것은 서로 다른 데이터 타입을 순서에 맞게 관리하는 것이 목적이므로 중괄호를 이용해 인덱싱을 많이 수행한다. 예를 들면 다음과 같다. 아래 예시에서는 ‘강아지가’ 라는 char형 데이터를 얻어오는 것이 목적일 것이다.
cell_A = {'우리집에는', 3, '마리', '강아지가', '있습니다'; '우리집에는', 2, '마리', '고양이가', '있습니다'}
cell_A{1, 4}
cell_A =
2×5 cell array
{'우리집에는'} {[3]} {'마리'} {'강아지가'} {'있습니다'}
{'우리집에는'} {[2]} {'마리'} {'고양이가'} {'있습니다'}
ans =
'강아지가'
그런데, 만약 위의 “A” 셀의 1 행만 떼다가 또 다른 셀로 만들고 싶다면 소괄호를 사용해 인덱싱 해야한다.
cell_B = cell_A(1, 1:end)
cell_B =
1×5 cell array
{'우리집에는'} {[3]} {'마리'} {'강아지가'} {'있습니다'}
struct형 배열(구조체)
struct형 배열은 “구조체”라고도 불리며 “필드(field)”라는 데이터 컨테이너를 사용해서 관련 데이터를 그룹화하는 데이터형이다. 앞서 cell형 데이터 타입에서도 언급되었다 싶이 “데이터 컨테이너” 안에는 어떠한 데이터형이라도 들어갈 수 있다. 그러면 cell을 쓰지 왜 struct형을 쓰느냐고 물을 수 있는데 struct형은 구조화된 데이터를 다루는데 유용하기 때문이다. “구조화”라는 말이 어렵게 들릴지도 모르겠지만 대략 이런 형식으로 나타낼 수 있는 것들을 의미한다.

그림 출처: Tree Structure, Wikipedia
위 그림은 “아주 단순화 시킨” 백과 사전의 구조를 보여주고 있다. 이처럼 만약, 백과 사전 데이터들을 다룬다고 하면 이처럼 구조화 되어 있는 데이터의 형태를 잘 표현해줄 수 있는 데이터 형식을 사용하는 것이 좋을 것이다.
struct형 배열의 생성
struct형 데이터를 생성할 때는 점 표기법을 사용한다. 말하자면, 아래와 같이 structName.fieldName의 형식으로 struct형 데이터를 생성한다는 뜻이다.
s.a = 1;
s.b = {'A', 'B', 'C'}
s =
struct with fields:
a: 1
b: {'A' 'B' 'C'}
struct형 데이터의 아이콘은 아래와 같은 모양이다.

struct형의 field가 struct형이 될 수도 있다. 위의 “Tree Structure” 그림의 예시를 아래와 같이 struct형으로 표현할 수 있다.
Culture.Art = [];
Culture.Craft = [];
Encyclopedia.Science = [];
Encyclopedia.Culture = Culture;
아이콘들을 이용해 구조를 표현하자면 아래와 같을 것이다.

struct형 배열의 참조 방법
struct형 배열을 생성할 때 점 표기법을 사용한 것 처럼 struct형 배열의 내용물을 할 때에도 점 표기법을 사용한다. 가령 아래와 같이 my_struct라는 구조체를 생성했다고 하면,
my_struct.a = 1:100;
my_struct.b = 100:-1:1;
아래와 같이 구조체의 필드들을 불러와 사용할 수 있다.
my_struct.a(1)
my_struct.b(2)
ans =
1
ans =
99
struct형 배열을 다룰 때 유용한 함수들
struct형 배열을 실전에서 다루면서 유용하다고 느낀 함수 몇 가지들을 소개하고자 한다.
fieldnames
구조체의 필드들은 순전히 이름을 가지고 불러와야 하는데 필드 개수가 많아지면 이름을 하나 하나 치면서 모든 필드의 데이터에 접근하는 것은 상당히 번거로운 일이다. “fieldnames” 함수를 이용하면 구조체의 필드 이름을 한꺼번에 받아올 수 있어서 유용하다.
my_struct.a = [];
my_struct.b = [];
fieldnames(my_struct)
ans =
2×1 cell array
{'a'}
{'b'}
rmfield
구조체 필드는 제거하기가 까다롭다. 벡터/행렬에서는 빈 벡터 []를 삽입하면 해당 원소가 삭제되지만 구조체는 필드에 빈 벡터를 삽입하면 원래의 내용물이 빈 벡터로 대체된다. 이럴 때 “rmfield” 함수를 사용하면 된다. (그렇지 않으면 Workspace의 구조체를 더블클릭해서 수동으로 삭제해줄 수도 있긴하다.)
my_sturct.a = [];
my_struct.b = [];
my_struct = rmfield(my_struct, 'a')
my_struct =
struct with fields:
b: []
orderfields
구조체 필드는 이름을 가지고 생성시키거나 참조하기 때문에 순서없이 쌓이게 된다. 만약, 여러 사람들과 하나의 구조체를 공유해 사용하는 경우 특정 이름의 필드가 들어가있는지 눈으로 파악하기 헷갈리는 경우가 많다. 이럴 때를 대비해서 필드명을 정렬해주는 함수인 “orderfields”를 사용하면 유용하다.
가장 대표적인 방법으로는 알파벳 순서대로 필드명을 정렬해주는 것이다.
my_struct.A = [];
my_struct.b = [];
my_struct.a = [];
my_struct.B = [];
my_struct
my_struct_ordered = orderfields(my_struct)
my_struct =
struct with fields:
A: []
b: []
a: []
B: []
my_struct_ordered =
struct with fields:
A: []
B: []
a: []
b: []
테이블형 배열
테이블형 배열은 흔히 테이블이라고 부른다. 테이블은 모든 데이터가 동일한 특성을 공유하고 있는 경우 사용하기 적합할 수 있다. 쉽게 말해서 “엑셀”에 넣기 좋은 형태의 데이터들을 테이블로 다루면 편리하다. 엑셀에서 데이터를 다루는 것 처럼 MATLAB의 테이블 데이터 타입에 포함되는 데이터 각각은 데이터 타입과 크기가 서로 다를 수 있다.
테이블형 배열의 생성
테이블형 배열, 즉 테이블을 생성하기에 앞서 테이블의 구조에 대해 먼저 생각해보자. 예를 들어, 5명 학생의 이름, 재수강 여부, 중간고사 성적, 기말고사 성적에 대한 데이터를 다룬다고 생각해보자. 가령 아래와 같은 형태를 지니고 있을 것이다.
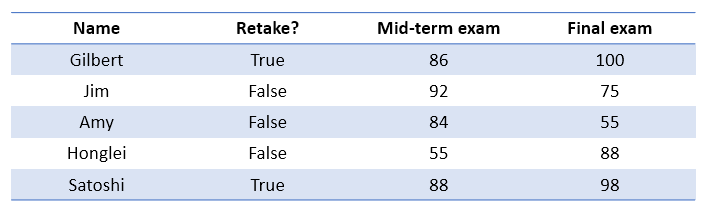
여기서 알 수 있는건 각 ‘열(column)’들은 각 열을 대표하는 이름을 가지고 있으며 각 열에는 동일한 타입의 데이터가 나열된다는 것이다. 테이블 변수를 생성할 때는 이런 구조를 그대로 가져와 MATLAB에서는 데이터에 포함된 “변수”들을 먼저 만들고 그 변수를 이용해 테이블을 생성한다.
name = ["Gilbert"; "Jim"; "Amy"; "Honglei"; "Satoshi"];
is_retake = [true; false; false; false; true];
midterm = [86; 92; 84; 55; 88];
final = [100; 75; 55; 88; 98];
T = table(name, is_retake, midterm, final)
T =
5×4 table
name is_retake midterm final
_________ _________ _______ _____
"Gilbert" true 86 100
"Jim" false 92 75
"Amy" false 84 55
"Honglei" false 55 88
"Satoshi" true 88 98
참고로 테이블형 데이터의 아이콘은 아래와 같다.
![]()
여기서 만약, “name”열에 들어있는 이름들을 행 제목으로 만들고 싶은 경우 아래와 테이블 변수 생성 시 따로 ‘rownames’ 를 “name” 으로 지정해주어야 한다.
name = ["Gilbert"; "Jim"; "Amy"; "Honglei"; "Satoshi"];
is_retake = [true; false; false; false; true];
midterm = [86; 92; 84; 55; 88];
final = [100; 75; 55; 88; 98];
T = table(is_retake, midterm, final, 'rownames', name)
T =
5×3 table
is_retake midterm final
_________ _______ _____
Gilbert true 86 100
Jim false 92 75
Amy false 84 55
Honglei false 55 88
Satoshi true 88 98
테이블형 배열의 참조 방법
테이블형 배열의 참조 방법은 cell형 배열의 참조 방법과 거의 유사한 방식을 따른다. 다시 말해, 소괄호 () 혹은 중괄호 {}를 이용해 테이블을 인덱싱할 수 있으며 소괄호 ()를 이용하면 테이블 덩어리를 가져오게 되고 중괄호 {}를 이용하면 테이블의 내용물을 가져오게 된다.
name = ["Gilbert"; "Jim"; "Amy"; "Honglei"; "Satoshi"];
is_retake = [true; false; false; false; true];
midterm = [86; 92; 84; 55; 88];
final = [100; 75; 55; 88; 98];
T = table(is_retake, midterm, final, 'rownames', name)
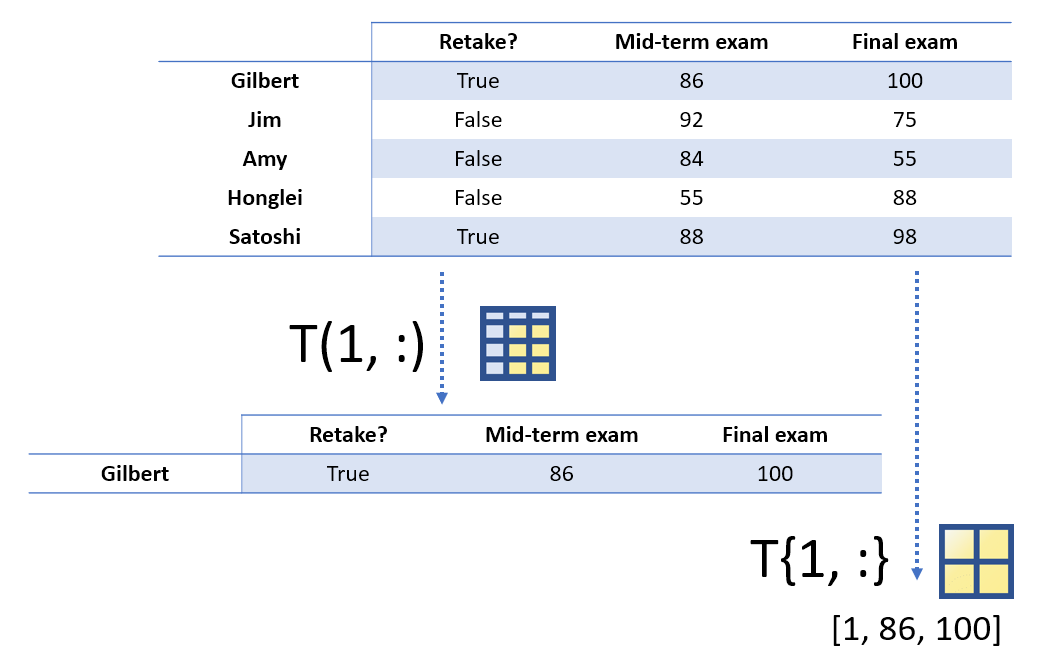
T(1, :)
T{1, :}
ans =
1×3 table
is_retake midterm final
_________ _______ _____
Gilbert true 86 100
ans =
1 86 100
만약 행 단위로 참조하고 싶은 경우 행 이름을 이용한 인덱싱을 사용할 수도 있다.
T("Gilbert", :)
T{"Gilbert", :}
ans =
1×3 table
is_retake midterm final
_________ _______ _____
Gilbert true 86 100
ans =
1 86 100
만약 열 단위로 참조하고 싶은 경우 열 이름에 대한 점 표기법을 이용해 참조할 수도 있다.
T{:, 3}
T.final
ans =
100
75
55
88
98
ans =
100
75
55
88
98
table형 배열을 다룰 때 유용한 함수들
table형 배열을 실전에서 다루면서 유용하다고 느낀 함수 몇 가지들을 소개하고자 한다.
head / tail
테이블의 맨 앞 부분 혹은 맨 뒷 부분 몇 개 데이터만 출력해준다. 테이블이 너무 길 때는 유용할 수 있다.
name = ["Gilbert"; "Jim"; "Amy"; "Honglei"; "Satoshi"];
is_retake = [true; false; false; false; true];
midterm = [86; 92; 84; 55; 88];
final = [100; 75; 55; 88; 98];
tblA = table(is_retake, midterm, final, 'rownames', name);
head(tblA, 2)
tail(tblA, 2)
is_retake midterm final
_________ _______ _____
Gilbert true 86 100
Jim false 92 75
is_retake midterm final
_________ _______ _____
Honglei false 55 88
Satoshi true 88 98
summary
테이블의 각 열의 정보를 요약해서 출력해준다.
name = ["Gilbert"; "Jim"; "Amy"; "Honglei"; "Satoshi"];
is_retake = [true; false; false; false; true];
midterm = [86; 92; 84; 55; 88];
final = [100; 75; 55; 88; 98];
tblA = table(is_retake, midterm, final, 'rownames', name);
summary(tblA)
Variables:
is_retake: 5×1 logical
Values:
True 2
False 3
midterm: 5×1 double
Values:
Min 55
Median 86
Max 92
final: 5×1 double
Values:
Min 55
Median 88
Max 100
sortrows
테이블의 행 순서를 정렬할 수 있다. 이 때, 특정 열의 값을 기준으로 하여 행을 정렬할 수 있다. 가령 아래와 같이 중간고사 점수를 기준으로 내림차순 정렬할 수 있다.
name = ["Gilbert"; "Jim"; "Amy"; "Honglei"; "Satoshi"];
is_retake = [true; false; false; false; true];
midterm = [86; 92; 84; 55; 88];
final = [100; 75; 55; 88; 98];
tblA = table(is_retake, midterm, final, 'rownames', name);
tblB = sortrows(tblA, 'midterm', 'descend')
tblB =
5×3 table
is_retake midterm final
_________ _______ _____
Jim false 92 75
Satoshi true 88 98
Gilbert true 86 100
Amy false 84 55
Honglei false 55 88
또, 행 이름을 기준으로 테이블을 정렬할 수도 있다. ‘RowNames’라는 옵션을 추가해주기만 하면 되는데, 이 때 ‘RowNames’는 대소문자를 구분해서 입력해야 한다.
tblC = sortrows(tblA, 'RowNames')
tblC =
5×3 table
is_retake midterm final
_________ _______ _____
Amy false 84 55
Gilbert true 86 100
Honglei false 55 88
Jim false 92 75
Satoshi true 88 98
readtable / writetable
데이터를 주고 받을 때 가장 흔하게 사용되는 방법은 스프레드시트 형식의 파일을 이용하는 것이다. 따라서, 스프레드시트 형식의 파일을 다룰 수 있는 함수가 실전에서 아주 많이 사용된다.
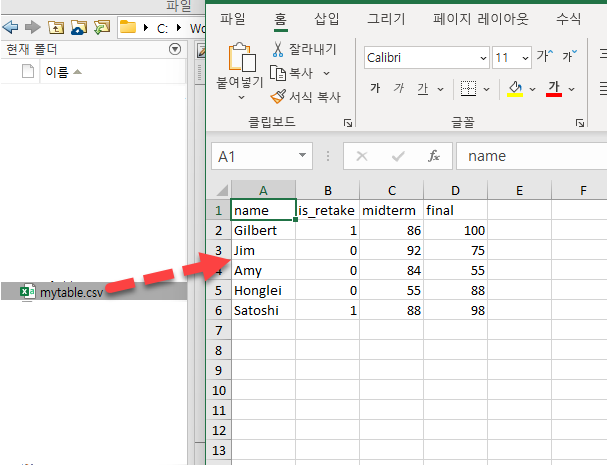
readtable 함수는 말 그대로 스프레드시트 형식으로 저장되어 있는 txt, csv, xlsx 파일등을 여는 기능을 한다. 만약 아래와 같은 “mytable.csv” 파일이 있다고 가정해보자.
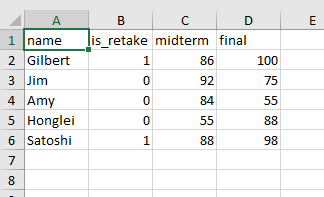
가장 간단하게는 아래와 같이 “readtable” 함수를 이용해 엑셀 파일을 테이블 형식으로 불러올 수 있다.
tblA = readtable("mytable.csv")
tblA =
5×4 table
name is_retake midterm final
___________ _________ _______ _____
{'Gilbert'} 1 86 100
{'Jim' } 0 92 75
{'Amy' } 0 84 55
{'Honglei'} 0 55 88
{'Satoshi'} 1 88 98
writetable 함수는 테이블 변수를 파일에 써주는 역할을 한다. 기본적으로 “txt” 파일에 테이블 내용이 들어가게 되지만, “csv”, “xlsx”, “xml” 등 형식의 파일에 테이블 내용을 쓸 수도 있다. 아래는 txt 파일로 테이블 내용을 쓰는 경우이다.
name = ["Gilbert"; "Jim"; "Amy"; "Honglei"; "Satoshi"];
is_retake = [true; false; false; false; true];
midterm = [86; 92; 84; 55; 88];
final = [100; 75; 55; 88; 98];
tblA = table(name, is_retake, midterm, final);
writetable(tblA);
type tblA.txt
name,is_retake,midterm,final
Gilbert,1,86,100
Jim,0,92,75
Amy,0,84,55
Honglei,0,55,88
Satoshi,1,88,98
만약, 특정 파일 형식으로 저장하고 싶다면 확장자를 포함하여 파일명을 명시해주면 된다.
writetable(tblA, 'mytable.csv');
join
“join” 함수는 두 개의 테이블을 합쳐주는 역할을 한다. 그런데, 단순히 합쳐주는 것은 아니고 두 테이블에 동일하게 들어있는 변수를 기준 삼아 합쳐주는 기능을 수행해준다. 이렇게 설명하면 무슨 말인지 알아먹기 어렵기 때문에 아래의 예시 그림을 살펴보자.
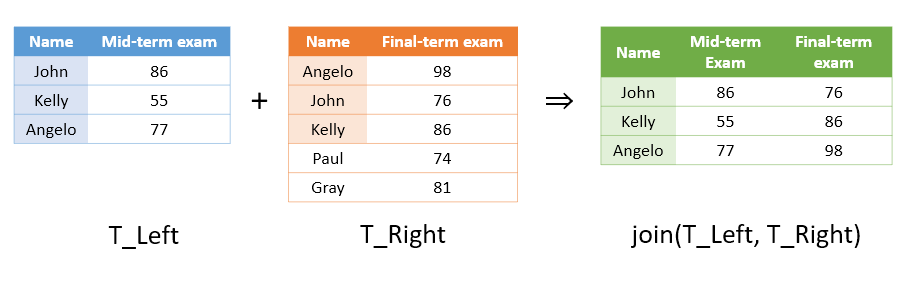
위 그림을 보면 “T_Left”와 “T_Right”가 공통적으로 “Name”이라는 공통 변수를 가지고 있다는 것을 알 수 있다. 공통 변수는 키 변수(key variable)이라고도 하는데, “join” 함수를 이용하면 오른쪽 테이블의 키 변수 값이 왼쪽 테이블의 키 변수값과 일치하면 왼쪽 테이블에 오른쪽 테이블의 내용물을 덧붙인다. “join” 함수가 편리한 이유는 키 변수의 행의 순서가 같지 않더라도 “알아서” 왼쪽 테이블의 위치에 맞게 테이블들을 합쳐준다는 점이다.
name = ["John"; "Kelly"; "Angelo"];
midterm = [86; 55; 77];
T_Left = table(name, midterm);
name = ["Angelo"; "John"; "Kelly"; "Paul"; "Gray"];
finalterm = [98; 76; 86; 74; 81];
T_Right = table(name, finalterm);
T = join(T_Left, T_Right)
T =
3×3 table
name midterm finalterm
________ _______ _________
"John" 86 76
"Kelly" 55 86
"Angelo" 77 98
innerjoin
“innerjoin” 함수는 “join”과 유사한데, 두 테이블의 키 변수(key variable)들 중 겹치는 것들만 모아서 (즉, 두 테이블의 키 변수 교집합) 테이블들을 합쳐준다. 아래의 예시를 살펴보자.
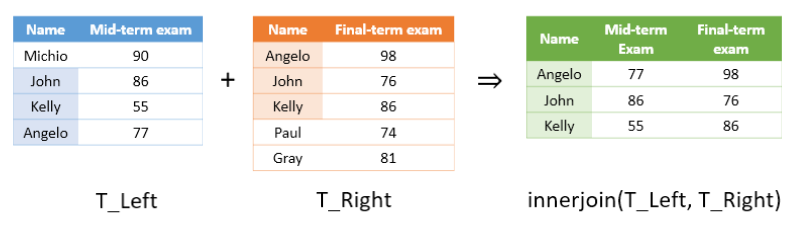
위 그림의 왼쪽 테이블과 오른쪽 테이블은 모든 키 변수를 공유하지는 않지만 부분적으로 공유하고 있는 것을 알 수 있다. “innerjoin” 함수는 부분적으로 공유된 키 변수들을 모아 새로운 테이블로 합쳐주는 기능을 하는 것이다. 참고로, “innerjoin”의 결과 테이블은 행 이름이 알파벳 순으로 정렬되어 출력된다.
name = ["Michio"; "John"; "Kelly"; "Angelo"];
midterm = [90; 86; 55; 77];
T_Left = table(name, midterm);
name = ["Angelo"; "John"; "Kelly"; "Paul"; "Gray"];
finalterm = [98; 76; 86; 74; 81];
T_Right = table(name, finalterm);
T = innerjoin(T_Left, T_Right)
T =
3×3 table
name midterm finalterm
________ _______ _________
"Angelo" 77 98
"John" 86 76
"Kelly" 55 86
만약 위와 같은 예시에서 “join” 함수를 사용하려고 하면 아래와 같은 에러가 발생된다.
T = join(T_Left, T_Right);
Error using tabular/join</b>
The key variable for the right table must contain all values in the key variable for the left table.
</span>
outerjoin
“outerjoin” 함수는 두 테이블의 키 변수들을 모두 모아서 (즉, 두 테이블의 키 변수 합집합) 새로운 테이블로 합쳐주되, 빠진 값들은 더미 변수를 채워주는 식으로 작동한다. 아래의 예시 그림을 보자.
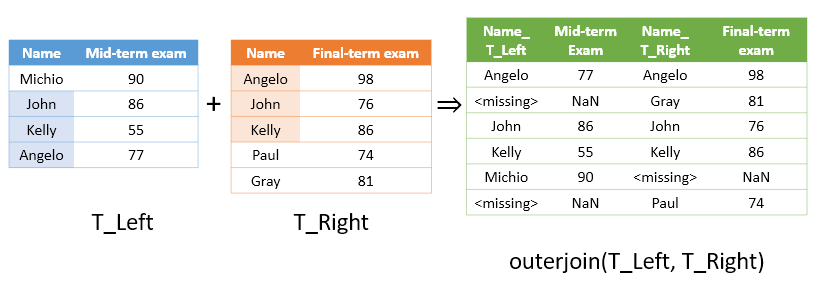
위 그림에서 확인할 수 있는 것 처럼 “outerjoin” 함수는 모든 키 변수들을 모아서 새로운 테이블을 생성해준다. 이 때, string형 문자열에서 빠진 값은 “Missing” 으로 표기하고 숫자 중 빠진 값은 NaN (Not a Number)로 표시한다.
그런데, 만약, 입력으로 들어가는 왼쪽, 오른쪽 테이블들에 대한 열을 각각 생성하지 않고 키 변수들을 합쳐주고 싶다면 ‘MergeKeys’ 옵션을 사용할 수도 있다.
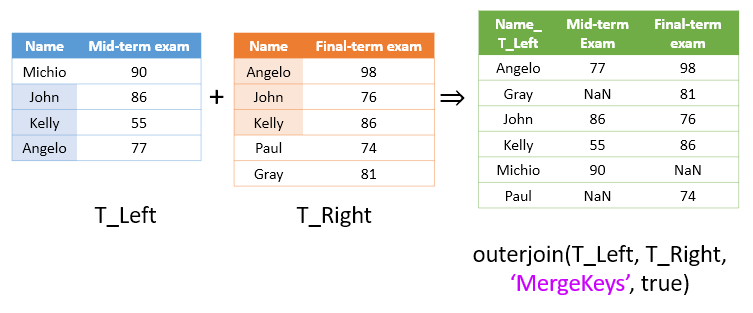
name = ["Michio"; "John"; "Kelly"; "Angelo"];
midterm = [90; 86; 55; 77];
T_Left = table(name, midterm);
name = ["Angelo"; "John"; "Kelly"; "Paul"; "Gray"];
finalterm = [98; 76; 86; 74; 81];
T_Right = table(name, finalterm);
T1 = outerjoin(T_Left, T_Right)
T2 = outerjoin(T_Left, T_Right,'MergeKeys', true)
T1 =
6×4 table
name_T_Left midterm name_T_Right finalterm
___________ _______ ____________ _________
"Angelo" 77 "Angelo" 98
<missing> NaN "Gray" 81
"John" 86 "John" 76
"Kelly" 55 "Kelly" 86
"Michio" 90 <missing> NaN
<missing> NaN "Paul" 74
T2 =
6×3 table
name midterm finalterm
________ _______ _________
"Angelo" 77 98
"Gray" NaN 81
"John" 86 76
"Kelly" 55 86
"Michio" 90 NaN
"Paul" NaN 74